IO 中的数据拷贝消耗
前言
IO 过程中的数据拷贝往往会消耗很多资源,受限于系统调用机制,语言机制等原因,可能存在无实际意义的多次拷贝,浪费更多资源。这篇文章举一个网络请求传输文件中数据拷贝的例子,让我们对一次 IO 中可能存在的关于数据拷贝的消耗有一个认识和了解,以及一些零拷贝技术,让我们有一些应对拷贝消耗的解决方案。
零拷贝技术是指计算机执行操作时,CPU不需要先将数据从某处内存复制到另一个特定区域。这种技术通常用于通过网络传输文件时节省 CPU 周期和内存带宽。
网络请求传输文件
直接使用 read,write:
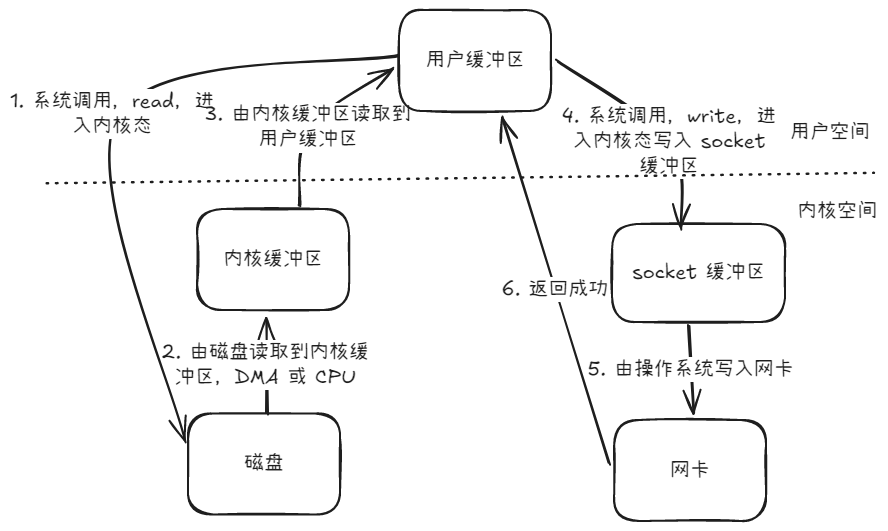
存在四次内存拷贝,两次系统调用的上下文切换:
- 磁盘到内核缓冲区
- 内核缓冲区到用户缓冲区
- 用户缓冲区到 socket 缓冲区
- socket 缓冲区到网卡
看起来是一次发送文件,其实是四次内存拷贝,如果是 Java 还要加一次堆外内存到堆内内存的一次用户空间的拷贝,真的很浪费。那么有没有什么办法减少这种浪费呢?
使用 send_file 优化:
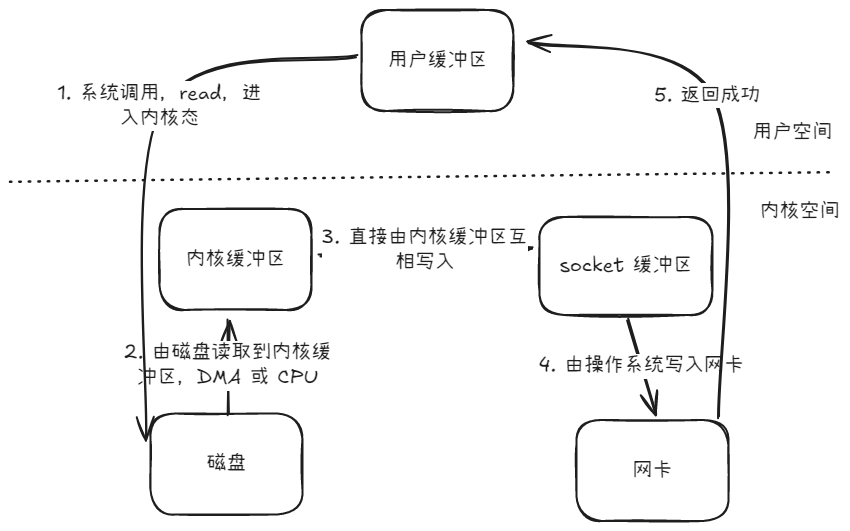
存在三次内存拷贝,一次系统调用上下文切换:
- 磁盘到内核缓冲区
- 内核缓冲区到 socket 缓冲区
- socket 缓冲区到网卡
减少了一次内存拷贝与一次系统调用上下文切换。
如何减少内存拷贝
针对这些 IO 中冗余的内存拷贝,操作系统针对不同的使用场景,提供了许多机制来减少拷贝。理解这些系统调用的原理,可以帮助我们选择相应的机制减少反复拷贝的消耗。
单纯优化发送文件的两种系统调用,使用场景比较狭窄,mmap 和 COW 使用场景比较丰富。
send_file
通常用于从文件系统真实文件的文件描述符向套接字文件描述符传输数据。
splice
通过管道在两个文件描述符之间传输数据。
mmap
mmap 并不是纯粹针对零拷贝的系统调用,我也列在这里了。
mmap 可以将文件直接映射到虚拟内存的地址空间,用内存读写代替文件读写,让操作系统缺页中断代替传统的 read,write 系统调用,不仅减少了内核空间和用户空间的数据拷贝的浪费,也减少了文件读取管理的复杂度(不用管理文件偏移量,可以像访问内存一样访问文件,也不用管理缓冲区)。
需要大量处理文件逻辑,并进行多次读写时,可以尝试使用 mmap,可以大幅度提升性能,同时还能减少管理文件读写的复杂度(这部分复杂度被托付给了操作系统),很难见到这种两方面都有提升的情况了。
一个使用 mmap 的优秀的例子就是 git。
COW
COW 是一种机制,并不是纯粹针对零拷贝的系统调用,我也列在这里了。
COW(Copy-On-Write)是一种延迟复制的技术,允许多个进程共享同一资源(如内存或文件),直到某个进程尝试修改资源时,才进行实际复制。这种机制显著减少了不必要的资源开销。
使用 COW 的有:
- fork:子进程共享父进程的内存空间,更改时才会复制,这让 fork 过程本身并不存在内存复制,效率很高,同时,何时进行延迟复制也托付给了操作系统,这部分复杂度用户没有感知。
- UnionFS: docker 的文件系统,通过 COW,在更改文件时生成新层,实现了底层镜像的只读与新镜像的生成,底层镜像的只读又进一步保证了不同容器间的隔离性以及共享的安全性。
总结
存在大量文件读写的场景下,可以多思考思考是否有机制可以针对性地进行优化。关于内存拷贝的优化更加底层,限制更多,实现更加困难了,很多时候语言并未提供接口,程序员也就束手无策了。
参考
原来 8 张图,就可以搞懂「零拷贝」了 - 小林coding - 博客园
【JAVA】普通IO数据拷贝次数的问题探讨 - shanml - 博客园
文档信息
- 本文作者:nyaaar
- 本文链接:https://nyaaarlathotep.github.io/2025/05/05/%E5%86%85%E5%AD%98%E5%A4%8D%E5%88%B6/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)